

A chess grandmaster glances at an unfamiliar position and within seconds understands it completely. They do not calculate every possible move. Instead, they recognize patterns drawn from tens of thousands of games, sensing which squares matter, which pieces carry hidden tension, and which threats deserve attention. When training a younger player, the grandmaster rarely dictates specific moves. They guide the apprentice through the reasoning itself, shaping how the student sees the board.
This same dynamic, pattern recognition developed through vast experience and transferred through mentorship rather than rules, underlies one of the most powerful approaches in modern medical imaging artificial intelligence.
The Two Ways Machines Learn
Supervised machine learning resembles a textbook in which every image carries a predetermined label. The system trains on thousands of annotated examples, learning to associate specific visual patterns with diagnoses such as stenosis, herniation, or normal anatomy. This approach performs reliably within its training distribution but struggles when encountering cases that deviate from labeled examples.
Unsupervised learning operates without labels. The system receives raw imaging data and must independently discover which features carry meaning, which cases resemble one another, and which findings represent outliers. Rather than memorizing associations, the model learns the underlying structure of the data itself.
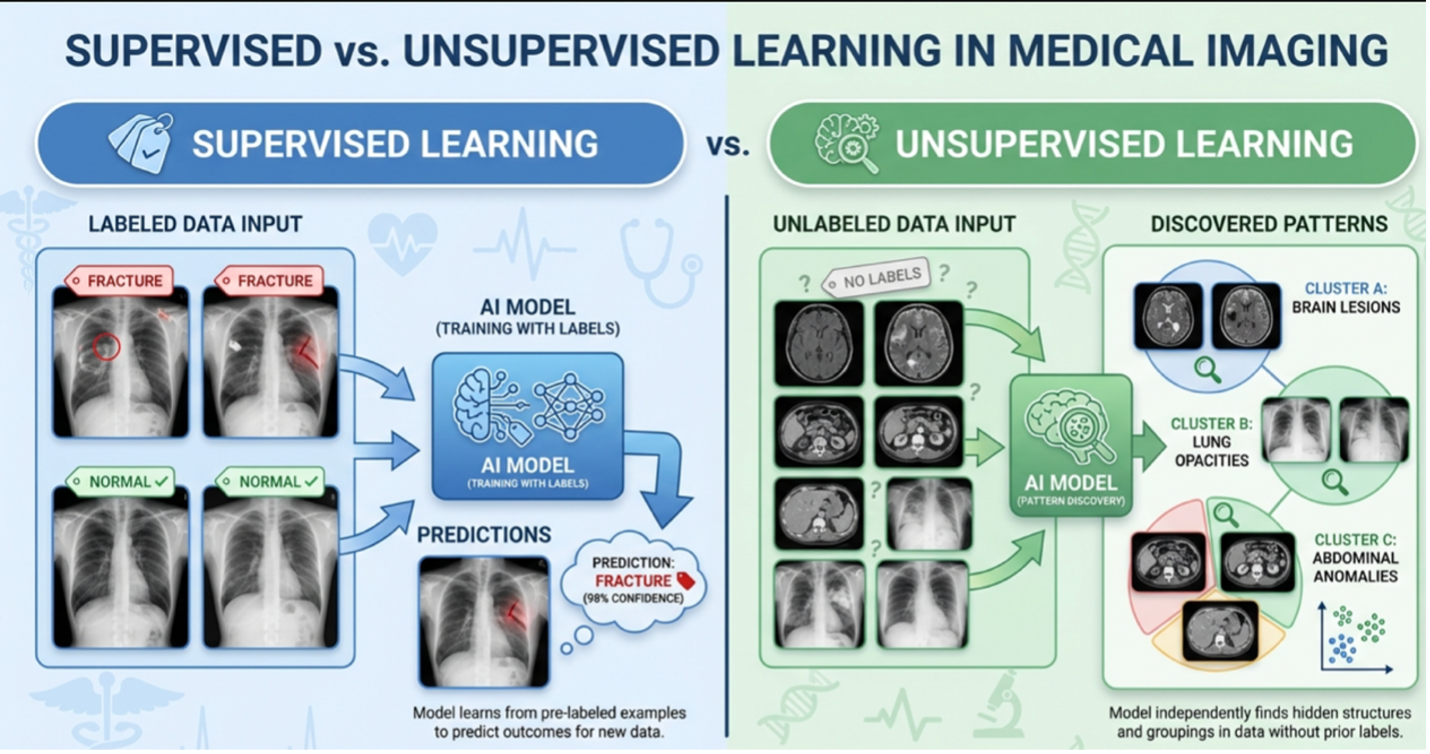
This distinction matters because high-quality labels remain scarce in medical imaging. Annotations are expensive to produce, often subjective, and frequently incomplete. Unlabeled imaging data, however, exists in abundance. Unsupervised learning allows artificial intelligence systems to develop diagnostic intuition from this vast corpus, much as a grandmaster develops positional intuition through the accumulated experience of analyzing countless games rather than memorizing a rulebook.
What Makes Vision Transformers Different
Traditional medical imaging algorithms process images hierarchically, analyzing small regions in isolation before gradually building toward a global understanding. This approach resembles how a novice chess player evaluates a position, examining one piece at a time without grasping the broader strategic picture.
Vision Transformers (ViTs) take a fundamentally different approach. They divide an image into small patches, analogous to puzzle pieces, and then evaluate all patches simultaneously. This parallel processing allows the model to understand how distant regions of an image relate to one another from the very first layer of analysis. Just as a grandmaster sees the entire board at once and instantly perceives how a knight on one side threatens a pawn structure on the other, a ViT grasps how distant regions of an image influence each other globally.
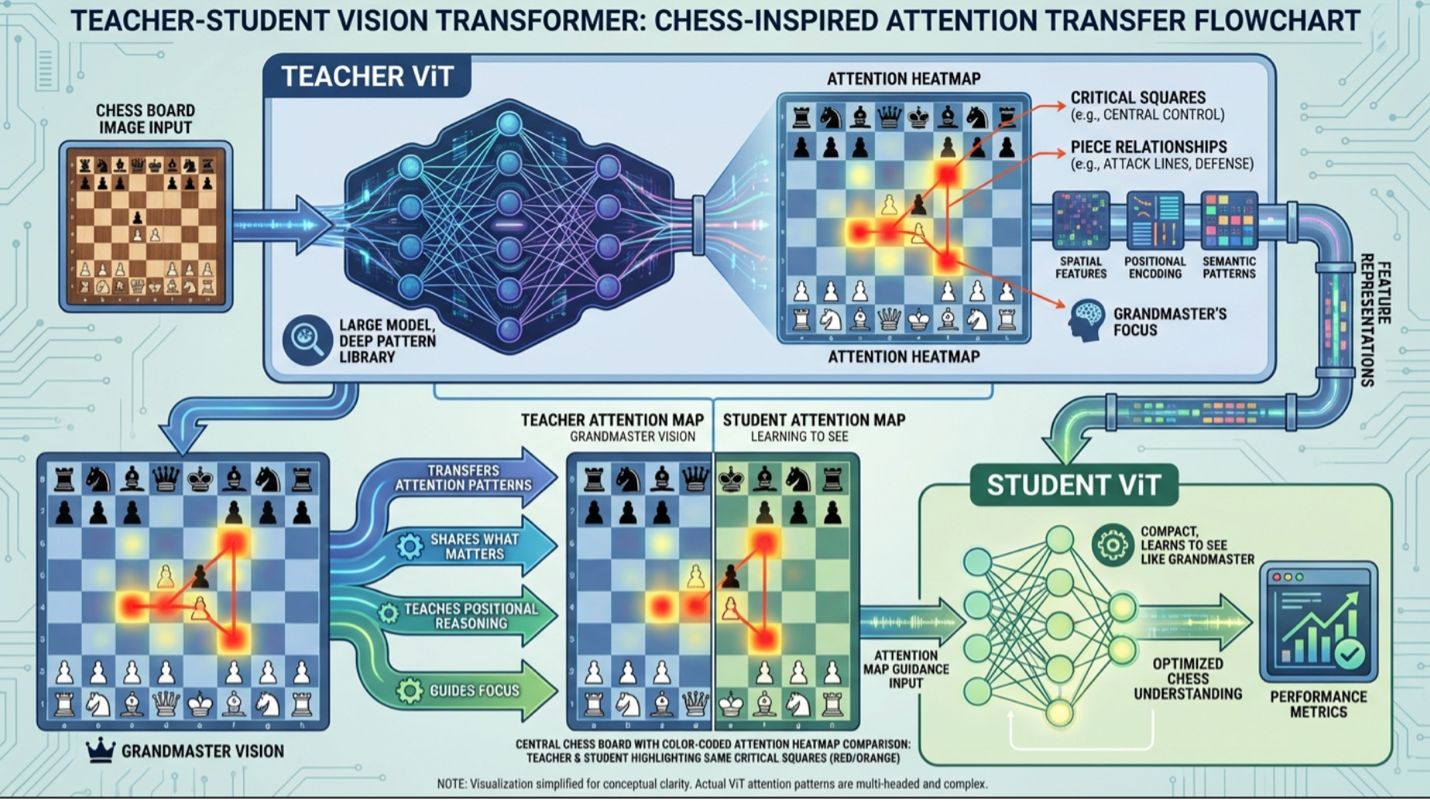
The Power of the Teacher-Student Relationship
The most effective Vision Transformers do not learn in isolation. They learn through a mentorship structure in which a sophisticated teacher model guides the development of a smaller, more practical student model. The teacher alone cannot be deployed at scale because its size and computational demands make real-time clinical use impractical, which is why a leaner student is necessary to bring expert-level reasoning into everyday imaging workflows. The true value of this framework lies in the quality of knowledge transfer itself.
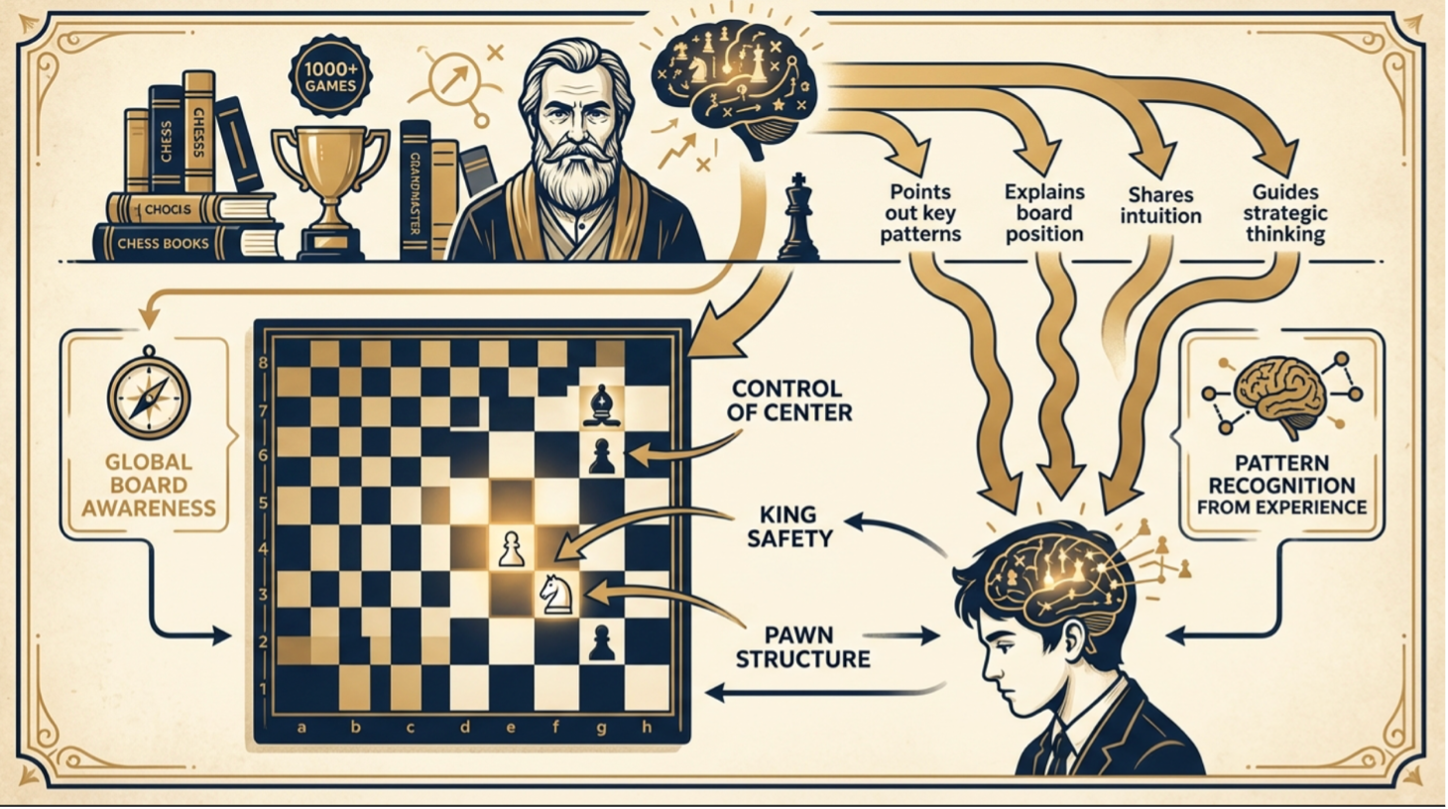
Effective mentorship rarely consists of dictating correct moves. A grandmaster guides the apprentice through the reasoning process, indicating where to direct attention, which piece relationships matter most, and which threats represent real danger rather than surface-level noise.
Teacher ViTs operate on the same principle. Rather than simply providing diagnostic labels, the teacher shares its attention patterns, feature representations, and judgments about relative importance. The student learns which patches matter, how they relate to one another, and how to distinguish meaningful signal from irrelevant noise. Through this process, the student acquires an approach to analysis rather than a catalog of answers.
Global Context and Comparative Learning
Experienced grandmasters evaluate positions in a specific hierarchical order, establishing the overall strategic picture before examining tactical details. They also rely heavily on comparative reasoning, recognizing that the position in front of them resembles a structure they have seen many times before, with meaningful variations that carry strategic implications.
Teacher ViTs reinforce both habits during training. The student learns to prioritize context before texture and relationships before isolated features. It also builds a continuous representation space in which similar cases cluster together and outliers occupy distinct regions. This geometry of similarity proves particularly valuable for conditions such as degenerative disc disease, where severity progresses along a continuum and subtle gradations carry clinical significance.
Correction Through Gradual Refinement
Strong mentorship rarely takes the form of binary right or wrong feedback. A grandmaster more commonly notes that the apprentice's idea was nearly correct but would benefit from additional attention to a specific part of the board. This graduated feedback supports steady skill development and calibrated confidence.
Teacher ViTs provide analogous soft targets rather than rigid binary labels. The student model minimizes its divergence from the teacher's nuanced output, which produces improved calibration. The resulting model handles diagnostic uncertainty in a manner that more closely resembles expert clinical judgment.
Mentored Students Develop Faster
Apprentices trained by strong grandmasters consistently develop skill more rapidly than players who learn in isolation. They make fewer catastrophic errors, develop positional intuition earlier, and achieve mastery with far less accumulated game volume.
Student ViTs demonstrate parallel advantages. Models trained through teacher guidance converge more quickly, require fewer labeled examples, and generalize more effectively to novel cases. This efficiency proves essential in medical imaging, where high-quality training labels remain a limiting resource.
The Student Teaches the Teacher
Perhaps the most elegant aspect of this framework is that the relationship flows in both directions. In competitive chess, a sharp student often discovers new ideas, challenges established theory, and pushes the grandmaster to refine their own understanding. Modern chess itself offers a striking example: AlphaZero, one of the strongest chess engines ever built, learned entirely through self-play, with each generation of the model teaching the next and both improving together.
The same dynamic operates in modern Vision Transformers. In frameworks such as self-distillation, the teacher model gradually incorporates the student's evolving knowledge through a running average of the student's parameters. As the student discovers new patterns and refines its representations, those insights flow back to update the teacher. The teacher consequently becomes stronger over time, which in turn provides better guidance to future students.
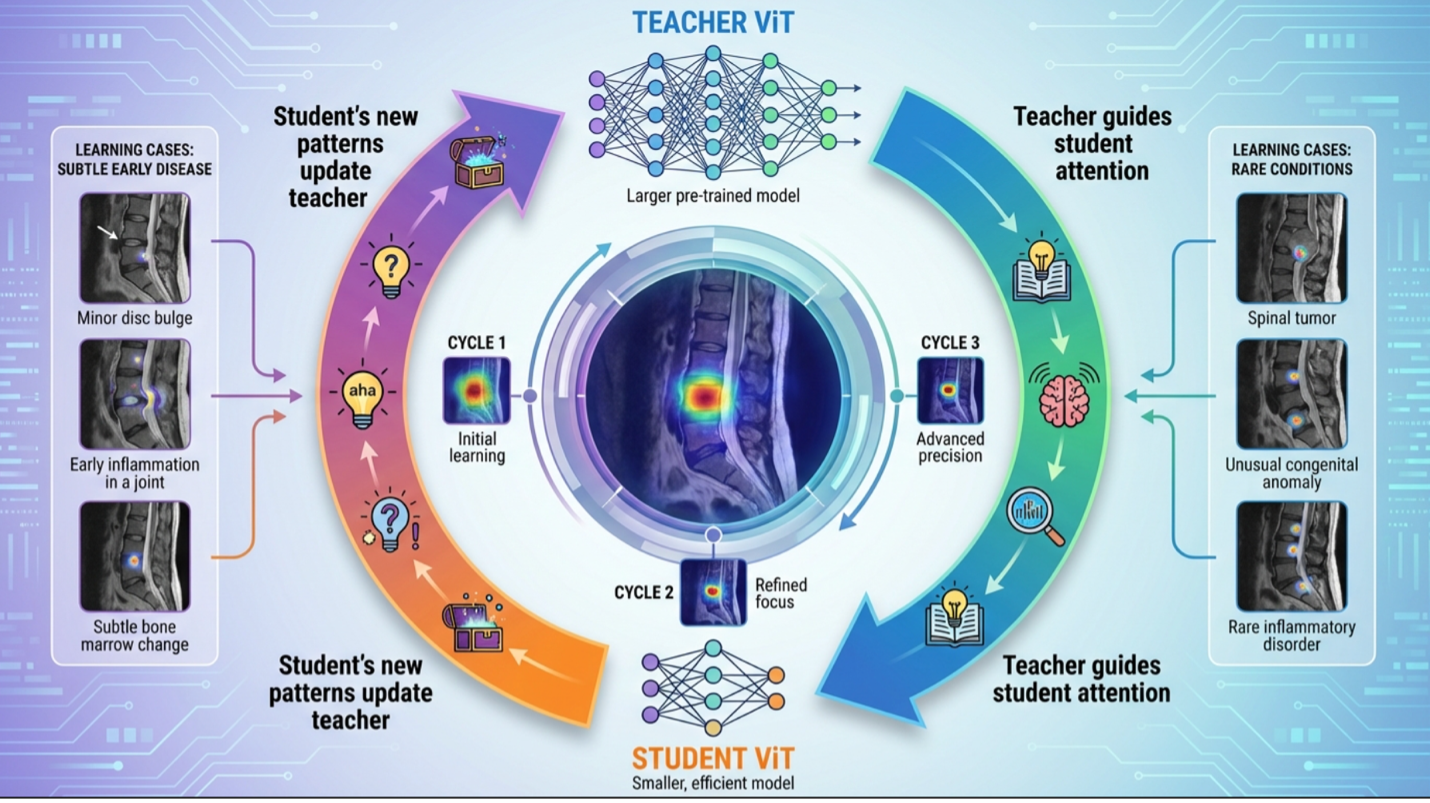
This bidirectional exchange has profound implications for medical imaging analysis. Consider a student model that encounters an unusual post-operative spine presentation the teacher has rarely seen. As the student develops stable representations for this variant, that understanding flows back and enriches the teacher's internal model of post-operative anatomy. The next generation of students inherits a sharper teacher, better equipped to handle the subtle variations that define real-world cases. Every unusual presentation, every rare variant, and every edge case the system encounters becomes a learning opportunity that strengthens the entire framework. The system becomes genuinely experiential rather than static, improving with every case it analyzes rather than remaining frozen at the point of initial training.
Clinical Implications for Surgeon Decision Making
Teacher-student ViTs excel specifically in the domains where conventional approaches struggle. They handle subtle early disease, continuous severity gradations, post-operative anatomy that departs from textbook patterns, variability across different scanner platforms, and the complex real-world cases that resist clean categorization. These advantages arise because the student has inherited a framework for reasoning rather than a rigid set of rules.
This capability extends beyond cataloging structural pathology. It adds a new layer of information that has historically eluded quantification, including longitudinal change, tissue durability, and the subtle trajectories that distinguish one patient's course from another. With these deeper insights, surgeons can make customized decisions tailored to the individual patient rather than relying on population-level heuristics.
Beyond Pattern Matching
The teacher-student framework represents a meaningful departure from conventional machine learning. It transfers ways of seeing, approaches to reasoning, and frameworks for handling ambiguity.
Critically, these insights keep surgeons at the center of medical decision making, empowering them to weigh complex management decisions with complete context. The distinction between a tool that identifies findings and a system that reasons about them defines the future of medical imaging artificial intelligence